
pandas DataFrame 인덱싱 종결
매우 자주 쓰지만 자주 쓰지 않으면(?) 자주 잊어버리게 되는 데이터프레임 인덱싱 방법에 대해서 이번 글로 종결하고자 합니다.
데이터프레임을 인덱싱하는 방법에는 여러가지 방법이 있습니다.
pandas 공식문서를 찾아보면 사용법을 익힐 수 있도록 간단한 예제 코드도 함께 있습니다.
데이터프레임?
데이터프레임(DataFrame) - pandas document
pandas.pydata.org/docs/reference/api/pandas.DataFrame.html#pandas.DataFrame
나는 리스트, 딕셔너리 등 자료형만 써왔는데?
최근 데이터프레임을 써보며 느낀 것은 리스트나 딕셔너리보다 코드를 간결하게 짤 수 있다는 것이다.
예제는 캐글 타이타닉 데이터를 사용해보겠습니다.
# 개발환경 : 구글 colab
import pandas as pd
df = pd.read_csv('/content/drive/MyDrive/dacon/titanic/test.csv')
df.head()
- DataFrame.loc
- 기본적으로 인덱싱이 라벨을 베이스로 한다.
Access a group of rows and columns by label(s) or a boolean array.
.loc[] is primarily label based, but may also be used with a boolean array.
- pandas.pydata.org/docs/reference/api/pandas.DataFrame.loc.html
데이터 조회
- 특정 행 데이터 불러오기
인덱스값을 통해 해당 행 데이터 또는 열조건까지 추가하여 데이터를 가져올 수 있습니다.
df.loc[0] # 특정 인덱스에 해당하는 데이터만 가져올 수 있고
df.loc[0,:] # 특정 인덱스에 열 조건으로 데이터를 가져올 수 있다
- 특정 열 데이터 불러오기
여기서 ":"은 전체로 이해하면 될거 같습니다. 첫번째 인덱스가 행에 해당하며,
전체 행에서 열 값이 'Name' 또는 'Fare'에 해당하는 값을 가져옵니다.
$ df.loc[:, ['Name', 'Fare']] # Name, Fare 열만 조회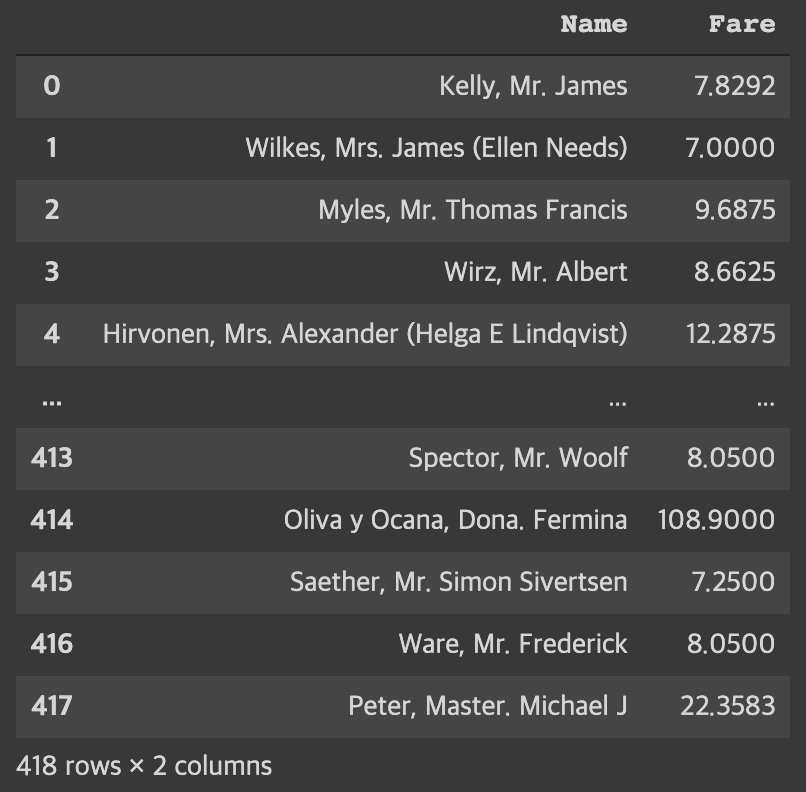
$ df.loc[:, 'Name':'Fare'] # Name에서 Fare까지 열 조회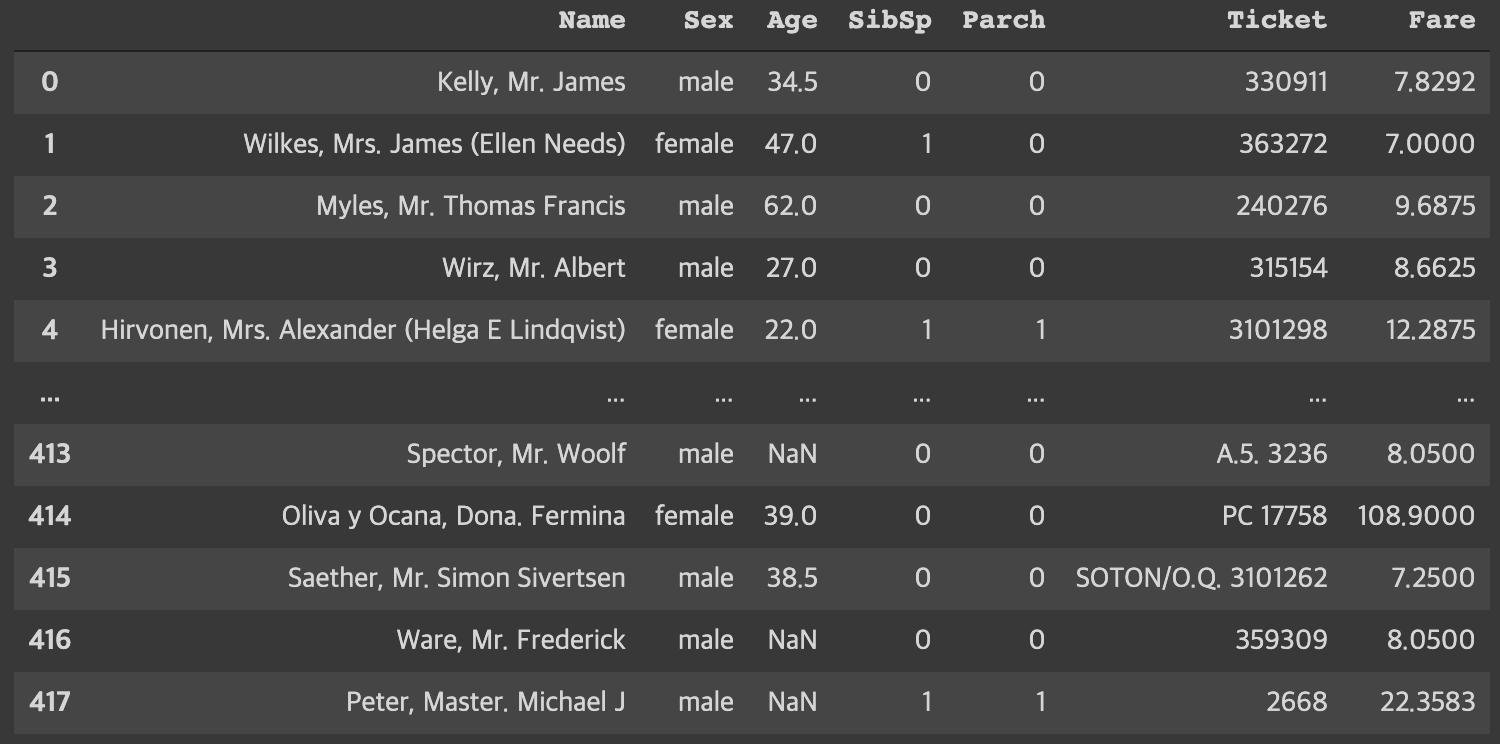
- 특정 열 값 기준으로 조회
엑셀로 치면 '데이터필터'와 같은 기능으로 특정 열값 기준으로 데이터를 뽑을 수 있습니다.
예를들어 성별이 여성(female)에 해당하는 데이터만 불러오려면 어떻게 해야할까요?
우선 아래와 같이 성별이 여성인 조건으로 찾아보면 Series 자료형으로 여성이면 True 아니면 False로 결과가 나옵니다.
$ df['Sex']=='female'
바로 이 bool array 에 해당하는 값을 인덱스로 데이터프레임 인덱싱으로 하고
결과적으로는 아래와 같이 특정 열 값 조건으로 조회를 해볼 수 있겠죠?
$ df.loc[df['Sex']=='female', :]
다중조건으로 가능합니다. 성별이 여성이고 나이가 50 보다 많은 조건으로 검색해봅시다.
컬럼은 Name, Sex, Age 만 불러와보죠.
참고로 이때 다중조건에는 반드시 괄호 ( ) 로 조건이 감싸져야 합니다.
$ df.loc[(df['Sex']=='female') & (df['Age'] > 50), "Name":"Age"]
데이터 삭제
- 결측치 포함되어 있는 행 삭제 : DataFrame.dropna()
우선, 데이터프레임에서 결측치에 대한 확인은 아래와 같습니다. 각 컬럼별 결측치 갯수 합계를 보여줍니다.
Age에 86개, Cabin에 327개 결측치가 포함되어 있네요.
$ df.isnull().sum()
$ df.shape # (418, 11)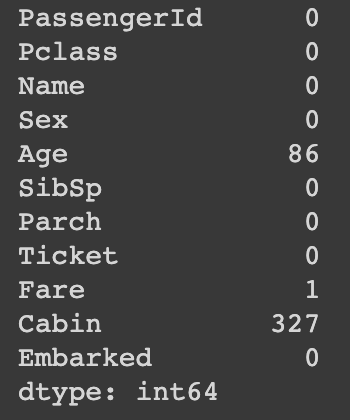
파라미터로 전달된 inplace=True 를 통해 기존 데이터프레임 객체를 그대로 사용할 수 있도록 바로 데이터프레임에 결과를 저장합니다.
$ df.dropna(inplace=True)정상적 결측치 제거 확인하고 Cabin에서 많은 결측치가 포함되어 있었기 때문에 결측치 포함한만큼 데이터가 삭제가 되었다.
$ df.isnull().sum()
$ df.shape # (87, 11)
- 중복데이터 행 삭제 : DataFrame.drop_duplicates()
나이별 갯수 카운트 하기 위해 Series.value_counts()로 조회해 보면,
24.0(24살, 데이터가 float 형이라 소수점) 이 17명 인 것을 알 수 있습니다.
$ df['Age'].value_counts()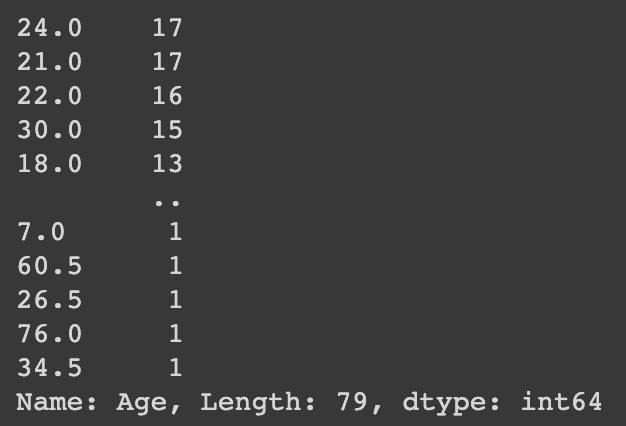
간단한 예제로 보여드리기 위해 데이터에 제한으로 나이가 64세 인 경우로 보여드리겠습니다.
$ df.loc[df['Age']==64.0, "Name":"Age"]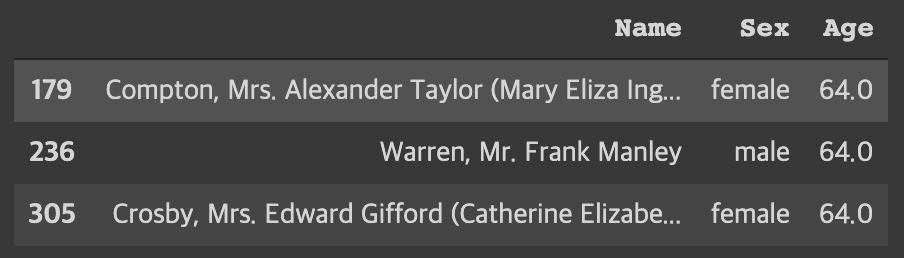
DataFrame.drop_duplicates() 에서는 중복을 체크할 컬럼명을 기입합니다.
또한 입력 파라미터로 "keep" 이라는게 있는데 중복 데이터 중 첫번째 값을 살릴꺼냐, 마지막을 남겨둘꺼냐 하는 역할을 합니다.
예제에서는 중복된 데이터 중 마지막 데이터만 남겨두는 방식으로 해볼게요.
$ df.drop_duplicates(['Age'], keep='last', inplace=True)데이터 결과를 확인해보면 마지막인 "Crosby"만 남겨두고 나머지는 삭제된 것을 확인 할 수 있습니다.
$ df.loc[df['Age']==64.0, "Name":"Age"]
- 특정 열(column) 조건에 따라 행 삭제
중복데이터 삭제에서 사용했던 나이가 64세 인 경우를 다시 한번 사용해 볼게요.
우선, 나이가 64세 인 조건에서 index 값을 가져옵니다. 이때 리턴값은 pandas 에서 indexes 자료형으로 넘어옵니다.
$ df[df['Age']==64.0].index위에서 구한 인덱스 값(삭제할 대상)을 DataFrame.drop() 을 통해서 제거 해줍니다.
$ df.drop(df[df['Age']==64.0].index, inplace=True)
- DataFrame.iloc
- 기본적으로 인덱싱이 인덱스 값을 베이스로 한다.
Purely integer-location based indexing for selection by position.
.iloc[] is primarily integer position based (from 0 to length-1 of the axis), but may also be used with a boolean array.
- pandas.pydata.org/docs/reference/api/pandas.DataFrame.iloc.html
df.iloc[0]
iloc는 다음 글에서 찾아 뵐게요!
'자기개발 > 데이터분석' 카테고리의 다른 글
| [머신러닝] k-NN(k-Nearest Neighbors) 알고리즘 학습 - 1)손글씨 분류 (0) | 2021.09.04 |
|---|---|
| [plotly] 시계열 시각화 X축 다루기 (0) | 2021.06.05 |
| [GIS] 행정동 통계격자지도 데이터 수집 방법 (0) | 2021.04.27 |
| [공모전] GTX 지하 대심도 철도사업 안전 아이디어 공모전 (0) | 2021.04.25 |
| [ERROR] ParserError: Error tokenizing data. C error: Expected 5 fields in line 3, saw 6 (0) | 2021.04.18 |